Easy Bayesian linear modeling
STA360 at Duke University
Examining the output
- Did
stan_glmdo what we think it did? Did the Markov chain converge?
Model Info:
function: stan_glm
family: gaussian [identity]
formula: mercury ~ .
algorithm: sampling
sample: 4000 (posterior sample size)
priors: see help('prior_summary')
observations: 171
predictors: 5
Estimates:
mean sd 10% 50% 90%
(Intercept) -1.4 0.3 -1.9 -1.4 -1.0
river -0.5 0.2 -0.8 -0.5 -0.3
station 0.1 0.0 0.1 0.1 0.1
length 0.1 0.0 0.0 0.1 0.1
weight 0.0 0.0 0.0 0.0 0.0
sigma 0.6 0.0 0.5 0.6 0.6
Fit Diagnostics:
mean sd 10% 50% 90%
mean_PPD 1.2 0.1 1.1 1.2 1.3
The mean_ppd is the sample average posterior predictive distribution of the outcome variable (for details see help('summary.stanreg')).
MCMC diagnostics
mcse Rhat n_eff
(Intercept) 0.0 1.0 2864
river 0.0 1.0 1857
station 0.0 1.0 1828
length 0.0 1.0 2814
weight 0.0 1.0 2861
sigma 0.0 1.0 2819
mean_PPD 0.0 1.0 3069
log-posterior 0.0 1.0 1616
For each parameter, mcse is Monte Carlo standard error, n_eff is a crude measure of effective sample size, and Rhat is the potential scale reduction factor on split chains (at convergence Rhat=1).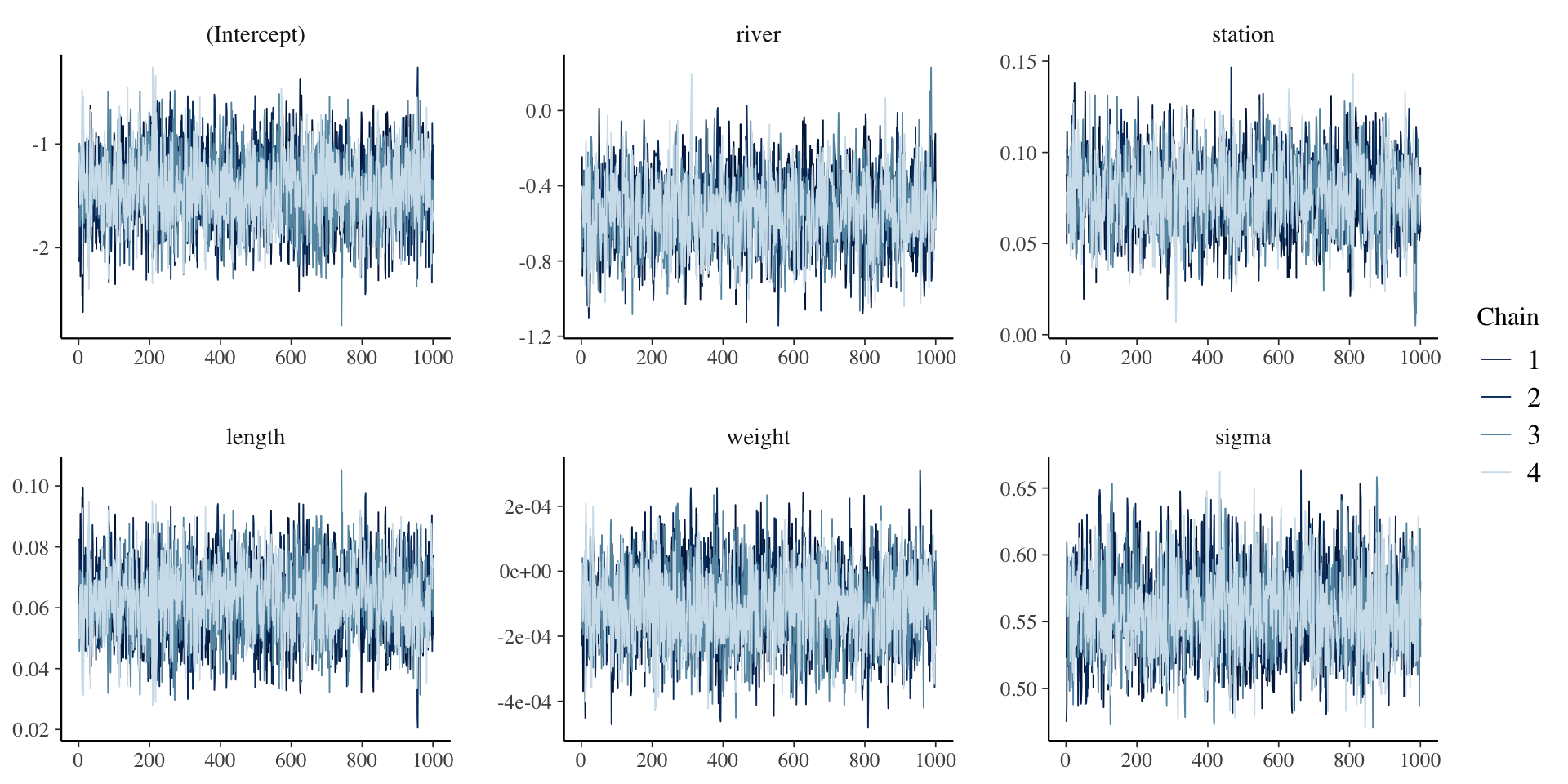
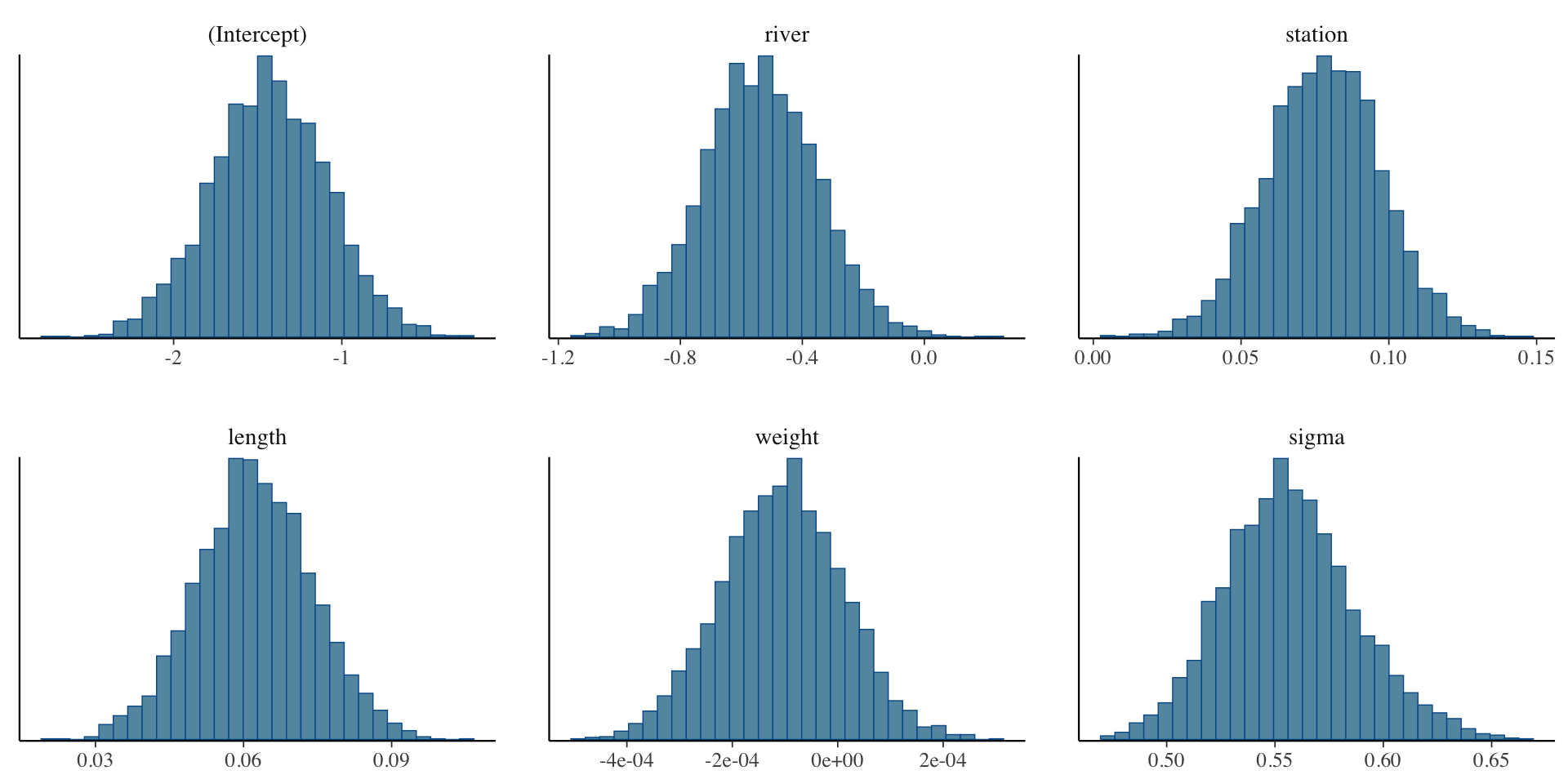
To plot specific parameters, use the arguemnt pars, e.g.
mcmc_trace(model1, pars = c("river", "station")mcmc_hist(model1, pars = "length")
To read more about bayesplot functionality, see https://mc-stan.org/bayesplot/articles/plotting-mcmc-draws.html
[1] "(Intercept)" "river" "station" "length" "weight"
[6] "sigma" ".chain" ".iteration" ".draw" [1] -0.3748586 -0.2472218 -0.8788921 -0.4870408 -0.6565987- try the following command:
View(chain_draws)
Report posterior mean, posterior median and 90% posterior CI.
posteriorMean = apply(chain_draws[,1:6], 2, mean)
posteriorMedian = model1$coefficients
posteriorCI = posterior_interval(model1, prob = 0.9)
cbind(posteriorMean, posteriorMedian, posteriorCI) posteriorMean posteriorMedian 5% 95%
(Intercept) -1.4320242215 -1.435098280 -2.0129526891 -8.767706e-01
river -0.5368486696 -0.538925449 -0.8441961657 -2.299097e-01
station 0.0777090920 0.078115486 0.0461303215 1.092244e-01
length 0.0622405968 0.062062419 0.0429862421 8.203404e-02
weight -0.0001059707 -0.000104737 -0.0002995203 8.105592e-05
sigma 0.5568710635 -1.435098280 0.5088456218 6.111942e-01